Natural language processing has been making huge progress over the last years and especially over the last few months. With models starting from GPT-3.5 to GPT-4 we saw that it is possible that models can “understand” and “reason” about our world if we train them on enough input text.
Language as it turns out is not such a bad way to encode knowledge about our world after all, even though it is often ambiguous and it is hard to clearly define what we want/mean (just watch “Suits” on Netflix if you haven’t ![]() )
)
So the question is, how can we leverage all the advances made in NLP and especially with GPT style models for our transaction data?
Understanding the Language of our Customers
As it turns out, there is a pretty straight-forward way we can do that. Consider the following:
Each time a customer comes to our stores and buys certain products, they speak to us. The language they speak depends on the products that we offer. They speak IKI, BILLA or Penny (remark: BILLA and Penny are supermarkets/discounters of IKI’s parent company REWE International Group) with us, depending on which supermarket/discounter they shop in.
Each product that they buy is a word they speak to us, and each receipt is a sentence. All receipts put together is the conversation they are having with us.
In our case, the order of the products on the receipts, i.e. the order of the words in each sentence, has no particular meaning, so the language does not really have a grammar. It is just a bunch of words, sort of like when kids start speaking when they are very young.
One of the first approaches to model natural languages was based on a model called “word2vec”. The basic idea is that we need to build a numeric representation of each word, so we can compare words to each other and understand their relationship. We call this numeric representation an embedding.
Obviously, there are lots of different ways how we can go about creating such embeddings. Consider the following words:
- Salami
- Bread
- Salami Sandwich
A very easy and straightforward way to create an embedding is to do it like this:
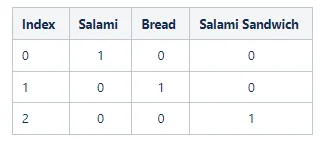
Each word is uniquely defined by a vector. However, this representation does not really tell us a lot about the relationship between the words. Clearly, a salami sandwich is a combination of salami and bread. So ideally, the numeric representation would also reflect that. One way we could achieve that is like this:
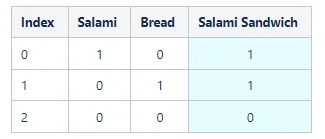
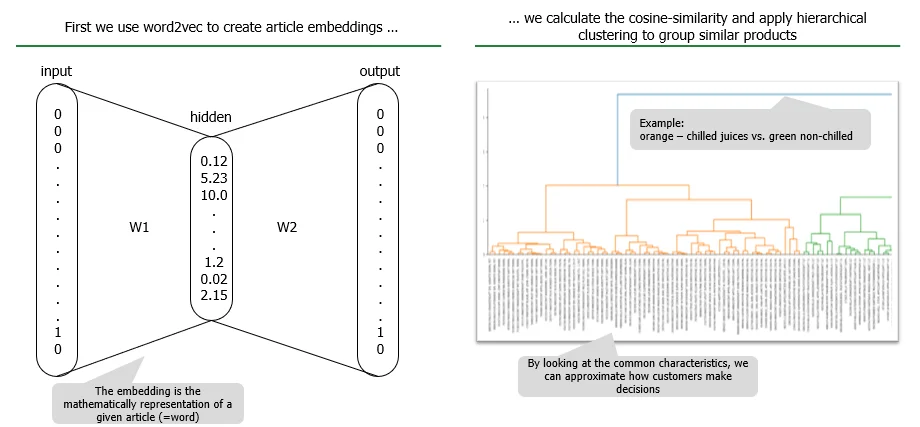
So the salami sandwich is now the sum of salami + bread, but salami and bread are still not related to each other. This brings us back to word2vec. Below you can see a chart that explains the underlying concept:
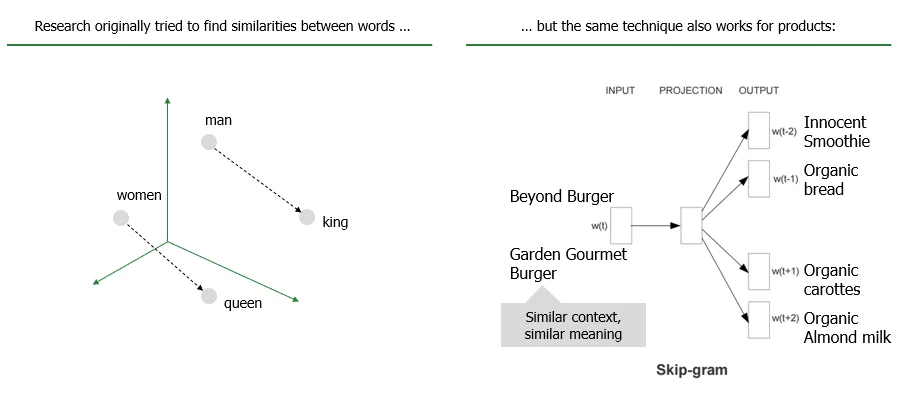
So in essence, we say that products that occur in a similar context (i.e. together with similar products) should have a similar numeric representation. As soon as we have that, the rest is just technical implementation of the optimization.
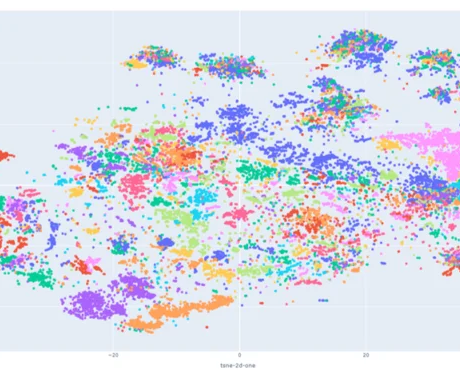
Now we can run word2vec and use the embeddings:
We can also use embeddings to calculate the meaning of “sugar-free” as discussed in the beginning:

GPT4 and all the other deep learning models apply the same underlying principles, they just utilize more complex network structures to model dependency across a longer context. But the core ideas are the same.
Hope you found our post interesting. If you are interested in understanding the language of your customers, feel free to reach out to us!

